No mundo das aplicações modernas, bancos de dados precisam ser muito mais que simples repositórios de informação. Eles precisam acompanhar o ritmo do crescimento dos negócios, lidar com picos inesperados de acesso, proteger dados sensíveis e, acima de tudo, funcionar sem intervenção manual constante. Uma dessas soluções que realmente chama a atenção é o Amazon DocumentDB, um banco de dados gerenciado e compatível com MongoDB.
A promessa é ambiciosa: entregar desempenho, escalabilidade e segurança com o mínimo possível de preocupação operacional. Mas como isso funciona na prática? O que há de especial nos recursos do serviço? E, o que sempre pesa na decisão, como calcular de fato quanto custa usá-lo no dia a dia?
Neste artigo, vamos mostrar os detalhes que você precisa saber. Desde a compatibilidade com MongoDB até a arquitetura de clusters, dos mecanismos de segurança até dicas de economia na operação — e, talvez o mais difícil, a visão clara da estrutura de custos, para que cada centavo investido faça sentido.
Você não precisa ser um especialista para gerenciar documentos na nuvem.
O que é o amazon documentDB?
Baseado no modelo de banco de dados de documentos, o Amazon DocumentDB foi criado para ser um serviço gerenciado, escalável e compatível com aplicações que usam MongoDB. Ou seja, para quem já desenvolve aplicativos usando esse banco NoSQL, migrar ou criar um ambiente baseado nele é bem menos complicado do que parece (como mostra a própria documentação oficial do Amazon DocumentDB).
Resumindo, trata-se de uma escolha para quem precisa armazenar, consultar e gerenciar dados em formato JSON de maneira flexível e ágil, com uma camada extra de tranquilidade pela automação de tarefas administrativas profissionais — backups, replicação de dados em regiões múltiplas, atualizações automáticas, monitoramento integrado e recuperação avançada.
Compatibilidade com mongodb: como funciona
Um dos maiores benefícios do serviço é a compatibilidade com as APIs e os drivers do MongoDB. Isso reduz significativamente o esforço para migrar aplicações já existentes, pois é possível reaproveitar boa parte dos códigos, operações e conceitos já familiares aos times.
Na prática, o mecanismo foi projetado para ser usado como backend de aplicações MongoDB. As conexões ocorrem via drivers nativos. A maioria dos comandos de leitura, escrita e agregação funciona do jeito esperado — claro, sempre vale verificar a lista de compatibilidade, já que recursos avançados podem variar de acordo com a versão.
A sensação de já saber usar um serviço novo, como se fosse uma extensão do ambiente anterior, é um alívio. Quem já enfrentou longas jornadas de adaptação para bancos de dados sabe o peso disso.
Menos tempo aprendendo, mais tempo inovando.
Como o serviço gerencia clusters e arquitetura distribuída
No coração do DocumentDB, está o conceito de cluster. Ele organiza grupos de instâncias, responsáveis por manter as réplicas dos dados sempre atualizadas. Cada cluster é composto de:
- Uma instância primária (responsável por leituras e gravações).
- Até 15 réplicas para leitura (aumentando a capacidade e a disponibilidade).
Sempre que há uma solicitação de escrita, a instância primária registra os dados. Réplicas servem para aumentar paralelismo de acesso, respondiam queries em alta escala e, principalmente, garantir rápida recuperação no caso de indisponibilidade.
Se algo acontecer com a instância principal, o mecanismo de failover automático entra em ação: uma das réplicas de leitura assume o posto, garantindo continuidade da aplicação praticamente sem pausa perceptível (mais informações técnicas sobre failover e réplicas). Isso é fundamental para negócios que não podem parar.
 Outro ponto de destaque: arquitetura distribuída por zonas de disponibilidade. Os dados são replicados em seis cópias, distribuídas em ao menos três zonas de disponibilidade diferentes. Isso eleva o patamar de durabilidade e reduz drasticamente riscos de perdas, mesmo diante de falhas em data centers inteiros. É difícil perder dados com essa abordagem (detalhes na página de recursos do serviço).
Outro ponto de destaque: arquitetura distribuída por zonas de disponibilidade. Os dados são replicados em seis cópias, distribuídas em ao menos três zonas de disponibilidade diferentes. Isso eleva o patamar de durabilidade e reduz drasticamente riscos de perdas, mesmo diante de falhas em data centers inteiros. É difícil perder dados com essa abordagem (detalhes na página de recursos do serviço).
Recursos avançados para segurança e disponibilidade
Criptografia embutida
Confidencialidade é mais do que um diferencial — é uma exigência legal, inclusive. O DocumentDB oferece criptografia em repouso e em trânsito usando chaves gerenciadas pelo AWS Key Management Service (KMS). Dados gravados só podem ser acessados por conexões seguras, e toda a movimentação ocorre criptografada (explicação sobre criptografia). Às vezes, parece apenas mais um item da lista. Mas quando ocorre o inesperado, faz toda a diferença.
Backup contínuo e recuperação point-in-time
Imagine precisar restaurar um dado exato, perdido por acidente há três dias. Sem backup, o desastre está feito. Por isso, o serviço mantém backup contínuo, com retenção de até 35 dias. É possível restaurar para qualquer instante dentro desse período — a chamada recuperação point-in-time. Interromper operações para restaurar tudo de uma vez? Não é mais necessário (detalhes sobre backup e retenção).
Erros acontecem. O segredo está em como você se recupera deles.
Escala sem interrupção
A necessidade de crescer ou reduzir o cluster pode surgir a qualquer momento. O Amazon DocumentDB permite:
- Aumentar ou diminuir a capacidade de leitura instantaneamente, adicionando/removendo réplicas.
- Redimensionar instâncias sem precisar migrar para outro ambiente.
- Expandir o armazenamento de maneira automática, em blocos de 10 GiB, até atingir 128 TiB, sem afetar a performance da aplicação (saiba mais sobre escalabilidade de clusters).
Para muita gente, basta saber que não será surpreendido por limitações rígidas. A flexibilidade de crescer conforme a necessidade isola equipes do pesadelo de prever tudo com antecedência.
Estrutura de custos: o que realmente importa
Agora talvez o ponto mais sensível: quanto custa usar o DocumentDB?
O modelo de cobrança precisa ser entendido em detalhe para não se perder nas surpresas da fatura. Há quatro grandes componentes:
- Instâncias sob demanda (CPU, memória e rede): pagas por hora, variando conforme tamanho e tipo da máquina virtual alocada.
- Storage (armazenamento de dados): cobrança por gigabyte provisionado e usado, expandindo automaticamente.
- I/O e transações (entrada e saída): quantidade de operações de leitura/gravação realizadas por segundo ou mês.
- Transferência de dados entre regiões: taxas extras quando há movimentação de dados entre diferentes regiões na nuvem.
Quem está começando pode se assustar pelo volume de linhas no demonstrativo. No entanto, a Amazon oferece explicações detalhadas dos preços para cada combinação de recurso. Então, vale simular alguns exemplos práticos — isso ajuda a calibrar expectativas e ajustar a arquitetura antes de colocar tudo rodando.
Como são cobradas as instâncias?
A cobrança principal recai sobre as instâncias que sustentam os clusters. Cada tipo de instância possui um valor/hora que se multiplica pelo número de horas rodadas no mês. Exemplos:
- Uma instância db.r6g.large ativa 24h/dia durante 30 dias resultaria em 720 horas/mês. Basta multiplicar o total pelo valor unitário/hora desse tipo na sua região.
- Se houver três réplicas de leitura, cada uma será cobrada à parte.
Na maioria dos projetos, a escolha do tipo certo é fundamental para evitar gastos sem necessidade. Há opções para workloads variados, desde aplicações de teste até clusters de produção robustos.
 Como funciona o custo de armazenamento?
Como funciona o custo de armazenamento?
 Como funciona o custo de armazenamento?
Como funciona o custo de armazenamento?O DocumentDB expande o storage conforme os dados crescem. Você paga apenas pelo que está ocupando, e o ajuste ocorre de 10 em 10 GiB, até o máximo de 128 TiB. Se os dados ocuparem 250 GiB no mês, a cobrança será nessa faixa — sem surpresas, sem precisar alocar espaço “sobrando” antecipadamente (explicação sobre expansão automática).
O interessante é que backups são cobrados apenas acima do tamanho do banco, ou seja, o primeiro backup é incluído. Só passa a existir custo quando as cópias de segurança superam o volume original das informações no cluster.
Custos de I/O e transferência
Se a aplicação exige muitas consultas e gravações, o valor das operações I/O pode crescer bastante. No modelo padrão, cada operação é tarifada após o uso mensal.
Para workloads que demandam um volume muito alto de operações, existe a configuração I/O-Optimized, que soma o custo de I/O já à tarifa da instância, e pode economizar até 40% em aplicações muito intensivas (detalhes sobre I/O-Optimized). Alguns casos se beneficiam muito, enquanto outros, com volume baixo a médio, ainda se saem melhor no modelo tradicional.
Transferências entre regiões
A movimentação de dados entre regiões é cobrada à parte, com valores extras para cada gigabyte transferido. Isso inclui cenários de replicação cross-region, failover global e até mesmo snapshots copiados para outras localidades para continuidade dos negócios.
Transferências dentro da mesma região, via VPC, normalmente não geram taxas.
Exemplo prático de cálculo de custos
Simular o total pode parecer complicado. Mas, colocando em números aproximados (não reais, apenas para ilustrar):
- Uma instância db.r6g.large rodando sozinha por 720 horas/mês custa X reais.
- Armazenamento de 150 GiB, mais 50 GiB de backups excedentes, soma Y reais/mês.
- Operações I/O mensalmente — digamos, 5 milhões — agregam Z reais.
Totalizando tudo, junta-se as linhas, vê quanto está gastando especificamente em cada recurso e pode adaptar o plano: reduzir réplicas, otimizar queries, passar para instâncias menores ou parar algumas em horários de menos uso. É um modelo modular — você “monta” sua fatura.
Entender onde está seu gasto é o primeiro passo para gastar menos.
Clustering elástico e operações de grande escala
Quando as aplicações crescem rapidamente, nem sempre é fácil prever quando vai precisar escalar. O DocumentDB oferece clusters elásticos, capazes de lidar com workloads de leitura e gravação que ultrapassam milhões de operações por segundo, armazenamento que pode atingir petabytes e adição ou redução instantânea de nós (detalhes nos clusters elásticos).
Um fluxograma rápido de escalabilidade envolve:
- Monitorar os picos de uso e crescimento.
- Adicionar réplicas de leitura conforme a demanda aumenta, sem impactar o ambiente.
- Expandir o storage sem precisar fazer migração manual de disco.
- Reduzir componentes automaticamente fora de horários de pico.
Quem opera aplicações de médio e grande porte sente a diferença: não há mais necessidade de agendar manutenções noturnas para migrar dados, comprar espaço extra só por precaução ou segmentar clusters manualmente.
Instâncias pausáveis e economia inteligente
 Instâncias pausáveis e economia inteligente
Instâncias pausáveis e economia inteligenteOutro destaque: é possível pausar instâncias de desenvolvimento ou teste, reduzindo drasticamente o custo nos períodos “ociosos”. Assim, você só paga pelo armazenamento enquanto os recursos computacionais não estão ativos. Em ambientes de produção, pode-se automatizar redimensionamento ou desligamento programado para equilibrar a relação custo-benefício.
Esse tipo de controle pode parecer supérfluo à primeira vista. Mas quem já se deparou com linhas e mais linhas de cobrança por ambientes esquecidos entende o valor de desligar aquilo que não está sendo usado.
Dicas e estratégias para otimizar custos
Reduzir custos é uma preocupação constante. Algumas atitudes simples ajudam nessa missão:
- Dimensione as instâncias de acordo com o uso real, começando pequeno e ampliando conforme necessário.
- Use o I/O-Optimized apenas para workloads realmente intensivos em operações por segundo.
- Pause instâncias de ambientes de desenvolvimento ou homologação sempre que possível.
- Acompanhe os painéis de monitoramento para identificar spikes e ajustar o ambiente preventivamente.
- Automatize tarefas de backup, limpeza e remoção de dados antigos para não exceder a cota de armazenamento e backup incluída.
 Erros mais comuns? Manter clusters rodando com excesso de réplicas. Não deletar bancos de teste ao final do projeto. Nunca olhar as métricas de uso de storage e I/O.
Erros mais comuns? Manter clusters rodando com excesso de réplicas. Não deletar bancos de teste ao final do projeto. Nunca olhar as métricas de uso de storage e I/O.
Gastar menos é, em grande parte, uma questão de disciplina.
Migração: como fazer sem dor de cabeça
Migrar dados pode ser um dos maiores medos — aquele receio de perder dados, ficar fora do ar ou descobrir incompatibilidades de última hora. A boa notícia é que, ao suportar APIs do MongoDB, ferramentas nativas de backup e restore funcionam para trazer dados históricos.
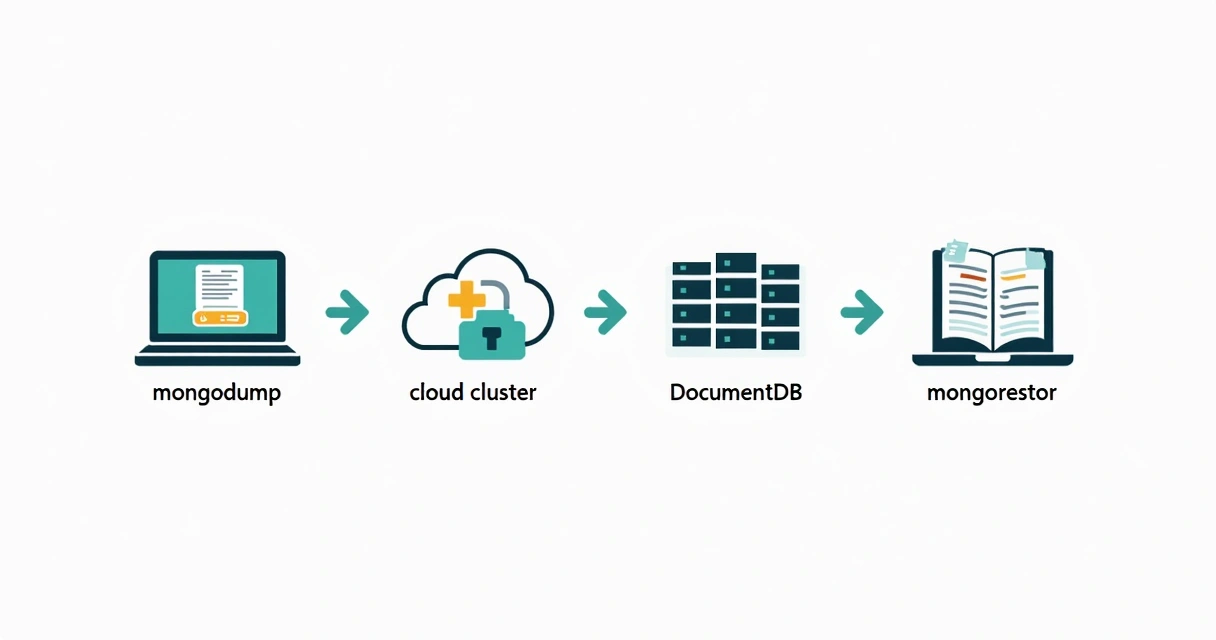
O processo costuma ocorrer assim:
- Executar um dump dos dados via comando mongodump, exportando coleções no formato BSON ou JSON.
- Transferir os arquivos para o ambiente do DocumentDB na nuvem.
- Executar o mongorestore, apontando para o cluster provisionado.
- Testar queries de leitura/escrita para checar se tudo reponde como esperado.
Não raro surgem pequenas diferenças em comandos específicos ou índices. Por isso, testar cada uso do sistema antes de liberar para produção é indispensável.
 E se desconforto persistir, vale usar uma instância de teste para simular tudo antes de executar a migração “pra valer”.
E se desconforto persistir, vale usar uma instância de teste para simular tudo antes de executar a migração “pra valer”.
Monitoramento e manutenção simplificada
Acionar alertas automáticos para consumo fora do padrão, visualizar tendências de crescimento de storage ou receber notificações de falhas: tudo isso vem integrado.
Usando os painéis de monitoramento nativos da AWS, é possível identificar rapidamente:
- Anomalias de performance.
- Consumo acima da expectativa.
- Possíveis gargalos de instância ou storage.
- Status de backups recentes e execução de restores automáticos.
A manutenção é reduzida a mínimos ajustes de configuração ou atualização de drivers, sem precisar gerenciar patches, upgrades de hardware ou orquestração manual de backups.
 É como ter um time de suporte disponível 24/7, mas sem a parte cansativa de intervenções toda semana.
É como ter um time de suporte disponível 24/7, mas sem a parte cansativa de intervenções toda semana.
Conclusão
Ao longo deste artigo, ficou claro que o Amazon DocumentDB é muito além de uma solução MongoDB gerenciada. Sua proposta cobre desde o conforto da compatibilidade até recursos focados em escalabilidade quase ilimitada, backup automático e mecanismos de recuperação confiáveis.
O diferencial está em três pontos: simplicidade operacional, robustez na proteção dos dados e liberdade para crescer sem interrupções. Quem enfrenta desafios para migrar um ambiente, manter aplicações em produção contínua e prever gastos, encontra neste serviço uma base segura para inovar.
Por outro lado, é fundamental compreender a estrutura de preços, monitorar operações e ajustar a configuração às reais necessidades. Isso faz toda a diferença ao final do mês.
Automatizar, escalar e proteger dados: tarefas que nunca deviam tirar seu sono.
Se você busca soluções flexíveis, escaláveis e seguras para aplicações que exigem agilidade no tratamento de dados em formato de documentos, o DocumentDB entrega exatamente isso — e torna menos assustadora a missão de crescer sob demanda, sem dores desnecessárias.
Perguntas frequentes sobre o amazon documentdb
O que é o Amazon DocumentDB?
O Amazon DocumentDB é um serviço de banco de dados gerenciado, orientado a documentos, projetado para ser compatível com o MongoDB, processando dados em formato JSON. Ele permite criar, operar e escalar bancos de dados de documentos na nuvem com alto desempenho, segurança integrada e automação de tarefas administrativas. Por ser compatível com a maior parte das APIs e drivers do MongoDB, facilita a migração de aplicações já existentes. A infraestrutura garante alta disponibilidade, réplicas automáticas e ferramentas de backup e recuperação. Mais detalhes na documentação oficial.
Como funciona a cobrança no DocumentDB?
A cobrança é dividida em quatro componentes: instâncias (CPU, memória e rede), armazenamento (storage usado e provisionado), operações de I/O (leituras/gravações), e transferência de dados entre regiões. Instâncias são cobradas em valor/hora conforme seu tipo e tempo de uso. O armazenamento é ajustado automaticamente conforme o crescimento dos dados, sem precisar alocar espaço extra. Operações I/O podem optar pelo modelo tradicional (por operação) ou pelo I/O-Optimized (tarifa fixa, recomendada para workloads muito intensos). Transferências de dados entre regiões têm custo extra por gigabyte. Sempre recomenda-se usar o simulador oficial antes de provisionar ambientes de produção. Veja exemplos práticos de preços.
Quais recursos o DocumentDB oferece?
Entre os principais recursos estão: compatibilidade com APIs MongoDB; clusters distribuídos com instância primária e até 15 réplicas de leitura; arquitetura de alta disponibilidade com seis cópias dos dados distribuídas por três zonas de disponibilidade; failover automático; escalabilidade de storage em blocos de 10 GiB até 128 TiB; criptografia de dados em repouso e em trânsito via AWS KMS; backup contínuo com recuperação point-in-time; monitoramento integrado; capacidade de escalar clusters elasticamente (milhões de operações/s e petabytes de storage); e possibilidade de pausar instâncias para economia. Confira a lista completa de recursos.
DocumentDB é escalável automaticamente?
Sim. O DocumentDB oferece armazenamento que cresce automaticamente conforme os dados aumentam, sem intervenção manual. É possível adicionar ou remover instâncias de leitura, subir ou descer a capacidade de computação das instâncias e crescer armazenamento até 128 TiB por cluster tradicional — e praticamente ilimitado em clusters elásticos. Configurações de escalabilidade automática ajudam a adaptar o ambiente a diferentes demandas, além de permitir pausar instâncias em horários de baixo uso para otimizar gastos. Leia sobre escalabilidade.
Vale a pena migrar para o DocumentDB?
A decisão depende do contexto de cada negócio. Para empresas que já usam MongoDB e buscam diminuir tarefas operacionais, aumentar a segurança dos dados, crescer sem barreiras técnicas e controlar custos, o serviço oferece vantagens consideráveis. A migração é facilitada pela compatibilidade e há benefícios claros em termos de backup, automação e escalabilidade. Por outro lado, analisar detalhadamente os requisitos, comparar custos simulados e ajustar o ambiente conforme a necessidade faz toda a diferença para obter vantagens reais. Para cargas intensivas em consultas e crescimento, o DocumentDB pode ser exatamente o caminho certo.





