Disaster Recovery é o conjunto de estratégias e processos que permite a uma empresa restaurar seus sistemas de TI após uma interrupção. Seja por falha técnica, ataque cibernético ou desastre físico, é ele o que separa um incidente de algumas horas de uma parada que custa milhões e pode abalar a confiança do cliente. Para qualquer líder de tecnologia, o tema pode gerar dúvidas porque mistura conceitos próximos (como backup, alta disponibilidade, plano de continuidade) e porque envolve métricas técnicas, como RTO e RPO. O resultado é que muitas empresas acham que estão protegidas quando, na prática, não estão.
Ao longo deste guia, você vai entender o que é Disaster Recovery, como ele funciona, quais são os cinco passos de um disaster recovery planning e como a UDS pode ser sua parceira neste momento:
O que é Disaster Recovery?
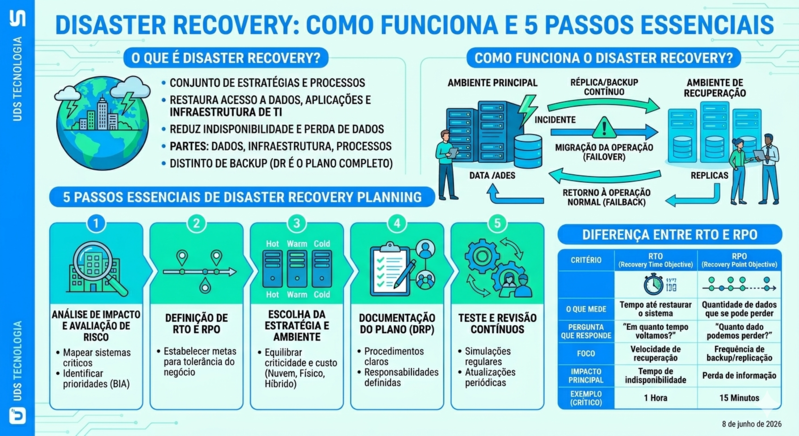
Disaster Recovery (recuperação de desastres) é a capacidade de uma organização restaurar o acesso a dados, aplicações e infraestrutura de TI depois de uma interrupção. Ele faz parte de uma estratégia ampla de continuidade de negócios e tem o objetivo principal de reduzir ao mínimo o tempo de indisponibilidade e a perda de dados quando, por problemas internos ou externos à operação, sistemas ficam fora do ar ou dados são perdidos.
Na prática, um Disaster Recovery cobre três frentes principais:
- Dados: réplicas e backups que garantem que a informação possa ser recuperada;
- Infraestrutura: servidores, rede e ambiente onde os sistemas voltam a rodar;
- Processos: os procedimentos documentados que a equipe segue para restaurar a operação com segurança.
Entenda em mais detalhes na ilustração a seguir:
Disaster Recovery é o mesmo que backup?
Vale uma distinção que costuma confundir: Disaster Recovery não é a mesma coisa que backup. O backup pode ser considerado uma das peças dessa estratégia, pois representa a cópia dos dados. Por sua vez, o disaster recovery é o plano completo de como colocar tudo de volta no ar a partir dessas cópias, em quanto tempo e em que ordem de prioridade.
Para entender como essas peças se encaixam, vale olhar o documento que as organiza:
O que é um documento de Disaster Recovery?
O documento de Disaster Recovery, também chamado de DRP (Disaster Recovery Plan), é o registro formal que descreve exatamente como a empresa vai responder a uma interrupção. A ideia é que ele explique como a equipe vai transformar a estratégia em instruções acionáveis. Assim, fica previsto em documento:
- Qual o papel de cada pessoa;
- Em qual sequência as ações devem ser realizadas;
- Quais recursos devem ser utilizados.
Além disso, um DRP bem estruturado costuma reunir:
- O inventário de sistemas críticos e suas prioridades de recuperação;
- Contatos e responsabilidades da equipe de resposta;
- Procedimentos passo a passo de restauração e as metas de RTO e RPO definidas para cada sistema.
A diferença entre ter esse documento e não tê-lo aparece, principalmente, no momento do incidente: sem ele, a equipe improvisa sob pressão, enquanto com ele, executa um roteiro já testado.
O que é um ambiente de Disaster Recovery?
O ambiente de Disaster Recovery é a infraestrutura secundária (que pode ser hospedada em nuvem, em data center alternativo ou híbrida) preparada para assumir a operação quando o ambiente principal falha. É para onde os sistemas e dados são replicados e onde a empresa continua operando durante o incidente. Esses ambientes variam conforme o quão rápido precisam assumir a operação:
- Um ambiente hot mantém réplicas ativas e sincronizadas, permitindo retomada em minutos ou segundos;
- Um warm mantém os sistemas prontos, mas exige alguma configuração antes de assumir;
- Um cold oferece apenas a infraestrutura básica, com tempo de recuperação maior e custo menor.
A escolha depende de quanta indisponibilidade cada sistema pode tolerar — e é exatamente isso que o planejamento define.
- Leia também: Recuperação de Desastres na Nuvem AWS: como prevenir incidentes e garantir a continuidade do seu negócio?
Como funciona o Disaster Recovery?
O Disaster Recovery funciona replicando dados e sistemas críticos em um ambiente secundário e definindo, com antecedência, como a operação será transferida para esse ambiente caso o principal fique indisponível. Quando ocorre uma interrupção, a empresa aciona o plano: a operação migra para o ambiente de recuperação (failover), os sistemas voltam a funcionar e, depois que o ambiente original é normalizado, a operação retorna a ele (failback).
Esse fluxo se apoia em quatro elementos que trabalham juntos:
Quais são os 5 passos de um Disaster Recovery Planning?
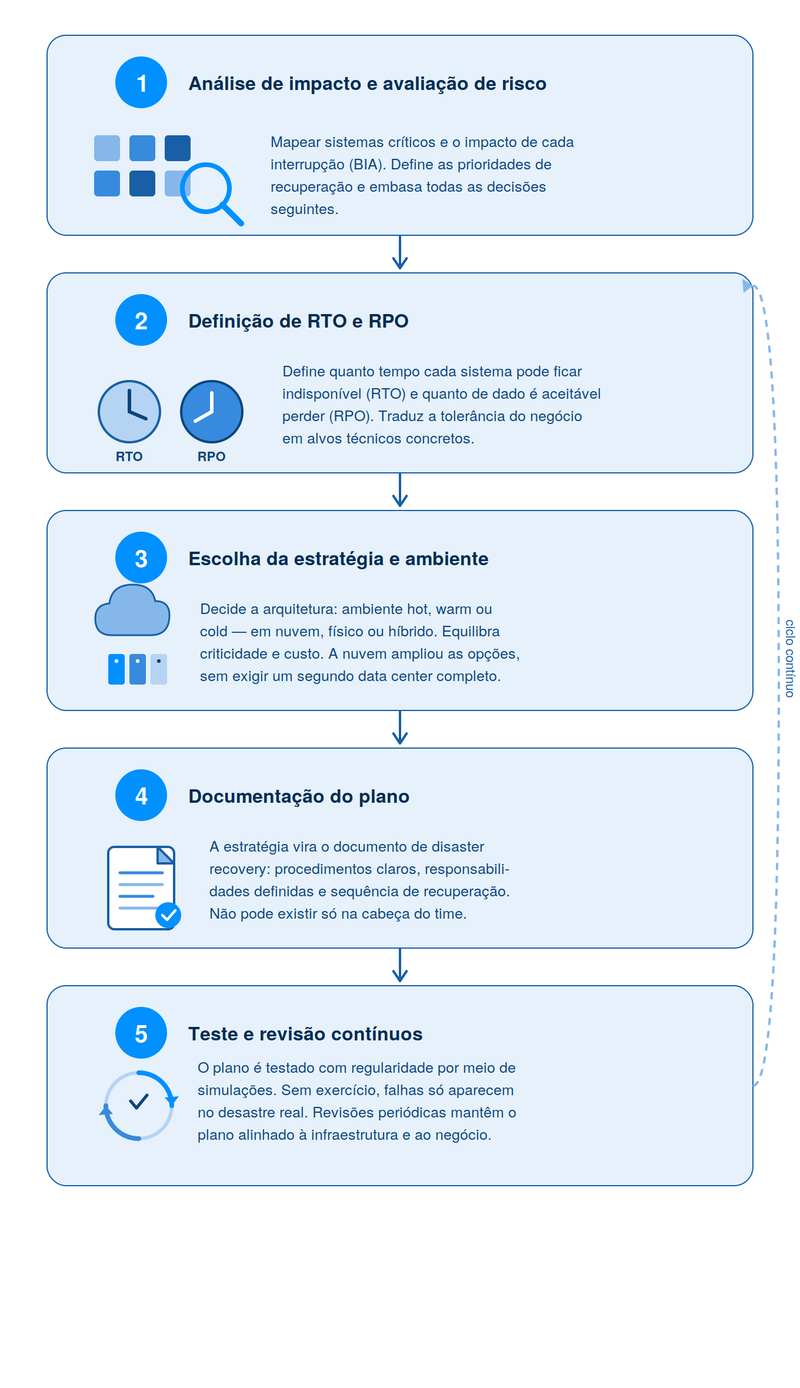
Um Disaster Recovery Planning estrutura-se em cinco passos que vão do entendimento do risco até o teste contínuo do plano. Seguir essa sequência evita o erro mais comum: ter um plano no papel que nunca foi validado e que pode causar consequências negativas, como falhas de recuperação justamente no momento em que ele é mais necessário. Entenda detalhes sobre cada passo:
1. Análise de impacto e avaliação de risco
Esta fase mapeia a infraestrutura para identificar quais sistemas são vitais para a geração de receita e o atendimento ao cliente, medindo o prejuízo financeiro e operacional que cada hora de inatividade causaria. Isso porque, sem esse diagnóstico claro, a empresa corre o risco de pulverizar investimentos de forma ineficiente, tentando proteger pequenas ferramentas administrativas com o mesmo orçamento e prioridade dedicados aos canais de venda principais.
O resultado prático dessa análise é um mapa de dependências que elimina os pontos cegos e os chamados “pontos únicos de falha”: ao quantificar o impacto de uma interrupção, a liderança ganha clareza para direcionar os recursos de segurança exatamente onde o risco de perda financeira ou de reputação é inaceitável. É a inteligência estratégica que transforma a segurança tecnológica em uma decisão de investimento inteligente e focada em resultados.
- Veja como reformulamos o ambiente de TI da Verocard com foco em resiliência e alta disponibilidade, garantindo Recuperação de Desastres Automatizada (DRaaS), resiliência de infraestrutura e zero downtime.
2. Definição de RTO e RPO
Com as prioridades estabelecidas, o passo seguinte é traduzir as necessidades de sobrevivência do negócio em metas técnicas viáveis: o RTO (tempo limite para o sistema voltar a funcionar) e o RPO (o limite de dados que a empresa aceita perder entre o último backup e o momento da falha). Esses dois indicadores funcionam como um termômetro de tolerância a perdas, ditando se a operação exige uma recuperação em minutos para não interromper o faturamento ou se pode aguardar algumas horas sem comprometer os resultados do mês.
Definir essas métricas de forma realista evita dois grandes erros: o subdimensionamento, que deixa o negócio vulnerável a prejuízos significativos, e o superdimensionamento, que encarece o projeto sem necessidade real. Por isso, encontrar esse equilíbrio garante a continuidade das operações com o melhor custo-benefício, alinhando as expectativas da diretoria com a capacidade de resposta imediata da equipe de tecnologia.
3. Escolha da estratégia e do ambiente de recuperação
Esta é a etapa onde equilibramos o nível de proteção com o orçamento disponível, escolhendo o modelo de arquitetura ideal (como nuvem, físico ou híbrido). O mercado trabalha com abordagens que variam desde soluções mais econômicas, onde os sistemas são reconstruídos a partir de cópias de segurança, até estruturas espelhadas em tempo real, onde um segundo ambiente assume o controle instantaneamente caso o principal falhe.
A tecnologia em nuvem revolucionou este cenário ao eliminar a necessidade de a empresa pagar e manter um segundo data center físico idêntico e ocioso. Assim, o foco aqui é desenhar uma estratégia inteligente de custos: investir em alta disponibilidade máxima para os sistemas vitais que geram receita direta e adotar modelos sob demanda e mais baratos para as demais ferramentas de apoio da empresa.
4. Documentação do plano
Para garantir a governança e a segurança institucional diante de uma crise, toda a estratégia precisa ser formalizada em um documento oficial. Não se trata de um manual complexo guardado em uma gaveta, mas sim de um guia completo que define papéis, responsabilidades, quem tem a autoridade para declarar um estado de desastre e qual a sequência exata que a organização deve seguir para se reerguer rapidamente. A formalização desse documento garante:
- Conformidade com auditorias de mercado;
- Proteção à reputação da marca perante clientes e investidores;
- Segurança de que a operação continuará protegida mesmo diante da rotatividade de profissionais-chave.
5. Teste e revisão contínuos
O teste periódico é a única garantia real de que o investimento feito em resiliência de fato funcionará quando a empresa mais precisar. Simulações regulares garantem que falhas de processo, novas atualizações de sistemas ou mudanças na equipe não tornem o plano obsoleto, transformando a segurança em parte da cultura corporativa e blindando a organização contra surpresas caras em um cenário real de crise.
Atualmente, o mercado utiliza testes modernos e não destrutivos, realizados em ambientes virtuais isolados e seguros. Contar com a expertise de uma parceira estratégica como a UDS permite que a sua empresa valide toda a capacidade de recuperação em horário comercial, sem interromper o trabalho dos funcionários ou a experiência dos clientes. Trata-se de uma auditoria prática de resiliência, que transforma o plano de continuidade em um ativo de segurança confiável e auditável para a mesa diretora.
Quais as diferenças entre RTO e RPO?
A diferença entre RTO e RPO está no que cada métrica mede: o RTO (Recovery Time Objective) define o tempo máximo aceitável para restaurar um sistema após uma interrupção, enquanto o RPO (Recovery Point Objective) define o volume máximo de dados que a empresa pode perder, medido em tempo. Em resumo, o RTO responde “em quanto tempo voltamos?” e o RPO responde “quanto dado podemos perder?”.
Os dois são complementares e juntos definem o nível de proteção de cada sistema. Uma instituição financeira, por exemplo, costuma operar com RTO de 1 hora e RPO de 15 minutos, pela sensibilidade das transações; uma operação industrial pode aceitar um RPO de 4 horas para dados não críticos.
| Critério | RTO (Recovery Time Objective) | RPO (Recovery Point Objective) |
| O que mede | Tempo até restaurar o sistema | Quantidade de dados que se pode perder |
| Pergunta que responde | “Em quanto tempo voltamos?” | “Quanto dado podemos perder?” |
| Foco | Velocidade de recuperação | Frequência de backup/replicação |
| Impacto principal | Tempo de indisponibilidade | Perda de informação |
| Exemplo (sistema crítico) | 1 hora | 15 minutos |
Definir esses dois números para cada sistema é o que transforma um plano genérico em uma estratégia sob medida e o que justifica, em termos de negócio, o investimento em cada nível de proteção.
Disaster Recovery com a UDS
Ao estruturar um plano de resiliência eficaz, contar com experiência em arquitetura de nuvem, domínio de métricas estratégicas e governança de segurança faz toda a diferença. A UDS Tecnologia atua há mais de 14 anos em Desenvolvimento de Software e Cloud Computing, consolidando-se como AWS Advanced Consulting Partner.
Em projetos de grandes marcas com operações complexas e alta exigência de disponibilidade, como Ambev, DHL e TOTVS, a continuidade dos sistemas não é negociável. É esse mesmo rigor analítico que orienta a forma como a UDS desenha ambientes de recuperação sob medida: dimensionados pela criticidade real de cada sistema, com RTO e RPO definidos lado a lado com as metas de negócio e planos exaustivamente testados. Se a sua operação não pode parar, fale com os especialistas da UDS para estruturar ou auditar o seu plano de Disaster Recovery.




