Na era digital, poucas coisas são tão críticas para uma empresa quanto manter seus sistemas e dados operacionais. Uma simples falha pode resultar em prejuízos milionários, perda de credibilidade e até mesmo a paralisação definitiva de um negócio.
Para enfrentar esses riscos, as estratégias de recuperação de desastres (DR) se tornam indispensáveis: elas reúnem práticas e ferramentas que permitem restaurar rapidamente operações de TI depois de incidentes que variam desde falhas tecnológicas e ataques cibernéticos até desastres naturais e erros humanos.
Neste artigo, vamos te explicar a importância, etapas e benefícios de ter um planejamento de recuperação de desastres, além de como o ecossistema AWS pode auxiliar na manutenção e segurança de dados da sua empresa.
O que é e como funciona na prática uma recuperação de desastres?
A recuperação de desastres está diretamente ligada à continuidade dos negócios. Seu principal objetivo é minimizar tempo de inatividade e perda de dados, possibilitando que a empresa retome suas atividades sem grandes interrupções.
Tipos de desastres que podem impactar empresas:
- Naturais: inundações, terremotos, furacões ou incêndios florestais;
- Ataques cibernéticos: ransomware, malware e ataques DDoS;
- Falhas tecnológicas: queda de energia, perda de conectividade, defeitos em servidores;
- Erros humanos: configurações incorretas, exclusões acidentais, falhas de operação.
Soluções de DR ajudam a restaurar dados e retomar operações por meio de backups automatizados, replicação de servidores e ativação de ambientes de contingência.
Para definir o quão robusta deve ser a recuperação, RTO (Recovery Time Objective) e RPO (Recovery Point Objective) são métricas essenciais. O RTO estipula quanto tempo um sistema pode ficar indisponível; já o RPO define a quantidade de dados que pode ser perdida sem causar danos irreparáveis ao negócio.
Importância da recuperação de desastres para empresas na era da nuvem
Com a computação em nuvem, criou-se um ambiente muito mais flexível e escalável para DR. Em vez de manter data centers próprios (e muitas vezes subutilizados), as empresas podem replicar dados na nuvem e ativar servidores sob demanda apenas quando necessário. Isso reduz custos e aumenta a eficiência, pois:
- É possível armazenar dados em diferentes regiões, o que evita que um único evento físico (como enchentes ou furacões) indisponibilize o ambiente completo;
- A conformidade regulatória se torna mais viável, já que muitas normas exigem planos de DR, e boa parte dos provedores de nuvem, como a AWS, oferece suporte a padrões de segurança e privacidade reconhecidos mundialmente.
Como a recuperação de desastres funciona?
Como vimos, a recuperação de desastres consiste em restaurar rapidamente processos de TI após uma interrupção. Ela combina práticas destinadas a reforçar a infraestrutura, prever situações de crise e responder de forma coordenada para reduzir perdas e manter a continuidade das operações. A seguir, estão três aspectos fundamentais que sustentam esse mecanismo.
➡️ Prevenção
A prevenção visa tornar os sistemas mais confiáveis e menos suscetíveis a falhas. Isso envolve o uso de tecnologias e métodos que reduzam o risco de incidentes causados por configurações incorretas, vulnerabilidades de segurança e erros humanos. Ao reforçar cada camada do ambiente, a organização diminui a chance de eventos críticos que prejudiquem o funcionamento normal do negócio.
➡️ Antecipação
A antecipação envolve simular potenciais desastres e planejar ações que facilitem uma recuperação rápida. Por meio de análises de risco, equipes especializadas avaliam situações passadas e, com base nisso, definem estruturas de backup e soluções de armazenamento em locais seguros. Esse trabalho prévio prepara a empresa para cenários de falhas inesperadas e garante maior resiliência quando elas ocorrem.
➡️ Mitigação
A mitigação ocorre quando o desastre já está em curso. Nessa etapa, a empresa ativa seus protocolos de emergência, orienta as equipes responsáveis e aciona recursos de contingência para restaurar serviços essenciais. Procedimentos de teste devem ser executados regularmente, e toda a documentação precisa estar atualizada para que, no momento crítico, as ações sejam coordenadas de forma assertiva e eficiente.
💡Leia também:
- O que é o Kiro AWS? Guia Completo para Times de Desenvolvimento
- AWS Certified Machine Learning – Specialty (MLS-C01): inteligência preditiva para empresas que pensam em escala
- AWS Certified Advanced Networking – Specialty (ANS-C01): conectividade, performance e segurança em escala corporativa
- AWS Certified Security – Specialty (SCS-C02): a certificação que protege o valor digital do seu negócio
- AWS Certified Solutions Architect – Professional (SAP-C02): arquitetando o futuro da nuvem corporativa

Tipos de recuperação de desastres
Diversos métodos podem ser adotados para restabelecer serviços de TI quando ocorre um incidente crítico. A seguir, estão algumas abordagens que variam em complexidade, nível de proteção e custo, contemplando desde simples backups até a orquestração completa de infraestrutura em ambientes alternativos.
1. Backups
A forma mais básica de recuperação, pois cria cópias de dados em locais separados. Embora proteja as informações, não abrange a retomada completa da infraestrutura de TI.
2. Backup como serviço (BaaS)
Modelo em que um provedor terceirizado efetua backups periódicos, aliviando a empresa de gerenciar esse processo. É mais automatizado e escalável do que o backup tradicional, mas ainda não cobre toda a arquitetura de TI em um cenário de desastre.
3. Recuperação de desastres como serviço (DRaaS)
Solução em que dados e infraestrutura são mantidos em nuvem por um provedor especializado. Em casos de falha, o provedor orquestra a restauração de sistemas e aplicações, reduzindo significativamente o tempo de indisponibilidade.
4. Snapshots pontuais
Método de replicar dados em pontos específicos do tempo. Útil para restaurar versões anteriores de arquivos ou bancos de dados, embora a frequência de criação dos snapshots influencie a quantidade de dados que pode ser perdida.
5. DR virtual
Mantém réplicas de sistemas e dados em máquinas virtuais. Essa abordagem permite recuperar operações rapidamente, pois basta reativar a réplica virtual em caso de interrupção, desde que o processo de transferência de dados seja feito com consistência.
6. Locais de recuperação de desastres
Centros temporários que a organização utiliza após um evento crítico. Esses locais já possuem backups, sistemas e infraestrutura indispensáveis para retomar as atividades, embora possam representar custos adicionais de manutenção.
Soluções AWS para recuperação de desastres
Em um cenário em que a disponibilidade de serviços é fundamental, a AWS oferece um ecossistema completo, cobrindo desde a prevenção de falhas até a restauração ágil de sistemas críticos. Confira como cada etapa de recuperação de desastres é contemplada:
Monitoramento e segurança
Serviços como AWS Config e Amazon Inspector rastreiam configurações e vulnerabilidades em tempo real, reduzindo riscos de falhas e ataques.
Replicação e backup
Cópias de dados em múltiplas regiões protegem contra interrupções locais. Amazon S3 e Amazon Glacier armazenam backups duráveis, enquanto o AWS Elastic Disaster Recovery replica servidores para agilizar a retomada.
Orquestração de failover
Em cenários críticos, o Elastic Disaster Recovery orquestra failover e failback rapidamente, acionando ambientes de contingência em poucos minutos. Esse processo garante restauração coordenada e menor tempo de inatividade.
Benefícios da recuperação de desastres com a AWS
A AWS traz vantagens significativas quando o assunto é DR:
- Redução de custos: graças ao modelo de pagamento por uso, as empresas não precisam manter infraestrutura ociosa, podendo ativar recursos apenas quando necessário;
- Recuperação rápida: o provisionamento automatizado de servidores e a replicação facilitada de dados aceleram a restauração de ambientes, reduzindo significativamente o tempo de inatividade;
- Segurança reforçada: criptografia, controle de acesso avançado (IAM) e certificações internacionais de conformidade tornam o ambiente seguro e resiliente;
- Flexibilidade e escalabilidade: recursos podem ser ajustados conforme a demanda, tanto em incidentes pontuais quanto em picos de uso, sem investir em hardware adicional.
Por que escolher a UDS para sua estratégia de recuperação de desastres?
A UDS destaca-se como parceiro AWS número 1 em serviços validados no mundo, com sólida experiência em projetos de missão crítica para diversos segmentos.
Além de ser especialista em arquitetura de software, cibersegurança e redução de custos, a empresa acumula resultados expressivos: mais de 900 clientes globais e 5.000 projetos entregues, incluindo casos de sucesso em otimização de custos e proteção de dados.
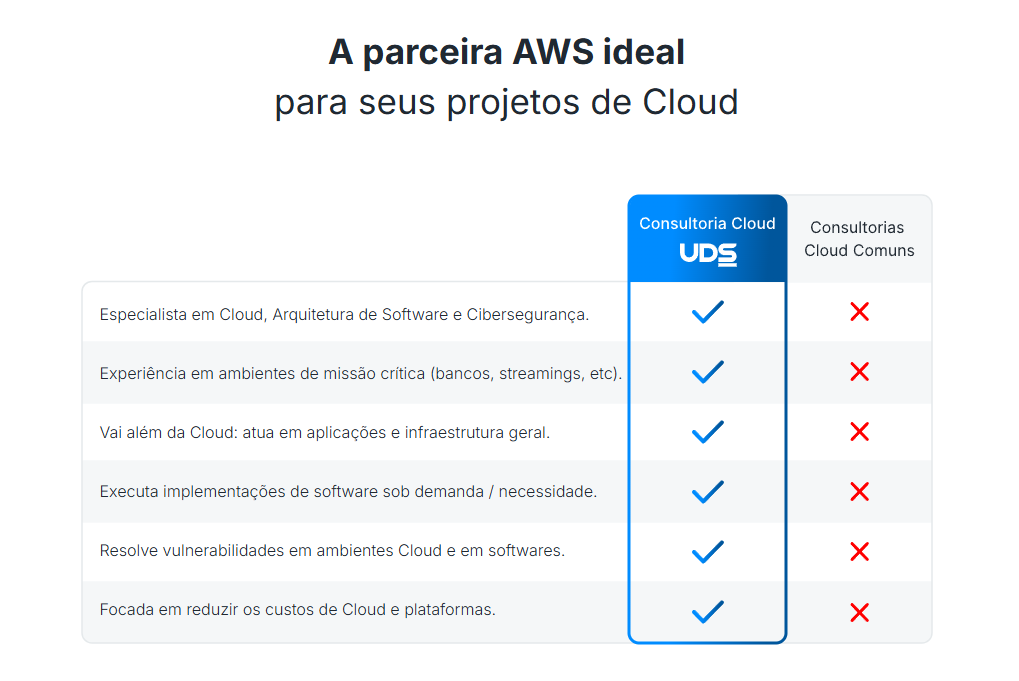
Suas soluções personalizadas incluem serviços gerenciados, migrações inteligentes e layers de segurança avançada, com o objetivo de garantir a continuidade dos negócios.
Por fim, a UDS tem a expertise necessária para desenhar, implementar e gerenciar sua estratégia de DR na AWS, o que garante continuidade, segurança e custo-benefício. Fale conosco agora e descubra como manter suas operações sempre ativas, independentemente do cenário.