Replicação de dados é o processo de manter cópias atualizadas das mesmas informações em mais de um local, de modo que, se um ambiente falha, outro assume sem que a operação pare. Ela representa uma das peças centrais de qualquer estratégia de disponibilidade e recuperação: enquanto o backup guarda uma cópia para restaurar depois, a replicação mantém os dados vivos e sincronizados em paralelo, prontos para entrar em ação a qualquer momento.
Se você é um líder de tecnologia, entender os tipos de replicação e quando usar cada um pode definir quanta indisponibilidade e quanta perda de dados a operação pode (ou não) tolerar, e quanto isso vai custar em infraestrutura.
Pensando em te ajudar, neste guia você vai entender o que é replicação de dados, como ela funciona, quais são seus tipos, quais as vantagens e como a UDS pode ser sua parceira nesse processo. Acompanhe:
O que é replicação de dados?
Replicação de dados é o ato de copiar e manter informações de um local de origem (o ambiente primário) para um ou mais ambientes de destino (os secundários ou réplicas), interligados por uma rede. Ao criar cópias dos dados em múltiplos locais, a replicação possibilita o acesso rápido aos dados em caso de falhas ou interrupções, mantendo a operação disponível mesmo quando o ambiente principal apresenta problemas.
Na prática, a replicação de dados trabalha sobre três elementos:
- Origem: o ambiente primário, onde os dados são criados e alterados;
- Destino: o ambiente secundário, que recebe e mantém as cópias atualizadas;
- Mecanismo de sincronização: o processo que identifica alterações na origem e as transmite ao destino, no ritmo definido pela estratégia.
A diferença em relação a um simples backup é que o backup é uma cópia pontual, feita para ser restaurada depois de um incidente, enquanto a replicação é contínua e mantém o dado pronto para uso imediato em outro ambiente.
Por isso a replicação costuma ser associada a conceitos como no-downtime ou near zero-downtime: a meta é reduzir ao mínimo, ou a zero, o tempo em que a operação fica indisponível.
Entenda detalhes sobre o funcionamento da replicação:
Como a replicação de dados funciona?
A replicação de dados funciona identificando em tempo real (ou em intervalos definidos) qualquer alteração feita no ambiente de origem — que pode ser o banco de dados principal da sua aplicação, um servidor local ou um sistema de gestão (ERP) — e transmitindo essas atualizações para um ou mais ambientes de destino (como servidores de backup, data warehouses ou a nuvem ).
Esse processo ocorre essencialmente em duas etapas:
- Captura de alterações (CDC): o sistema monitora e identifica qualquer inserção, atualização ou exclusão de informações nos dados originais (origem);
- Transmissão e aplicação: essas mudanças são enviadas pela rede e aplicadas nos repositórios de destino, garantindo que ambos os lados fiquem perfeitamente sincronizados.
O ponto de partida para qualquer estratégia é o fator tempo: a cópia precisa ser idêntica à origem em tempo real ou pode haver um pequeno atraso? Essa resposta define não apenas o tipo de replicação e o custo da infraestrutura, mas também o nível de proteção do negócio.
Portanto, é aqui que o planejamento se conecta diretamente às metas de RTO (Tempo de Recuperação Objetivo) e RPO (Ponto de Recuperação Objetivo) de um plano de continuidade: quanto menor for a tolerância à perda de dados, mais próxima do tempo real a replicação deve ser.
- Para entender como esse processo se integra a uma estratégia completa de segurança, confira o nosso guia de Disaster Recovery.
Quais são os tipos de replicação de dados?
A replicação de dados se divide em quatro modelos principais: replicação síncrona, replicação assíncrona, replicação baseada em log e replicação por snapshot. Cada um deles equilibra de forma diferente a consistência das informações, o custo de infraestrutura e a tolerância à perda de dados. Entenda melhor:
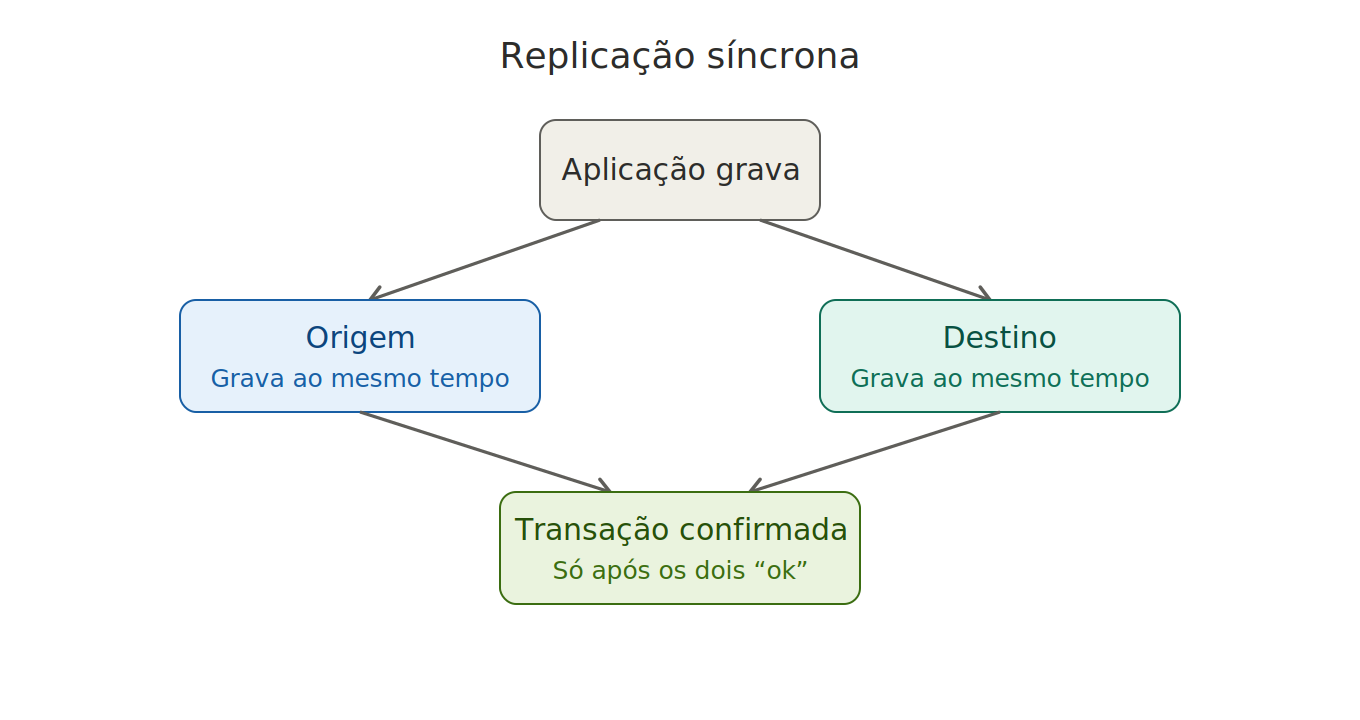
Replicação síncrona
Os dados são gravados na origem e no destino simultaneamente, e a transação só é concluída após a confirmação de recebimento em todos os pontos de armazenamento. Esse modelo garante perda de dados praticamente zero, sendo ideal para sistemas críticos, apesar de exigir conexões de altíssima velocidade (baixa latência) e maior investimento em infraestrutura.
- Quer evoluir sua operação com segurança e agilidade? Conheça a Consultoria Cloud da UDS.
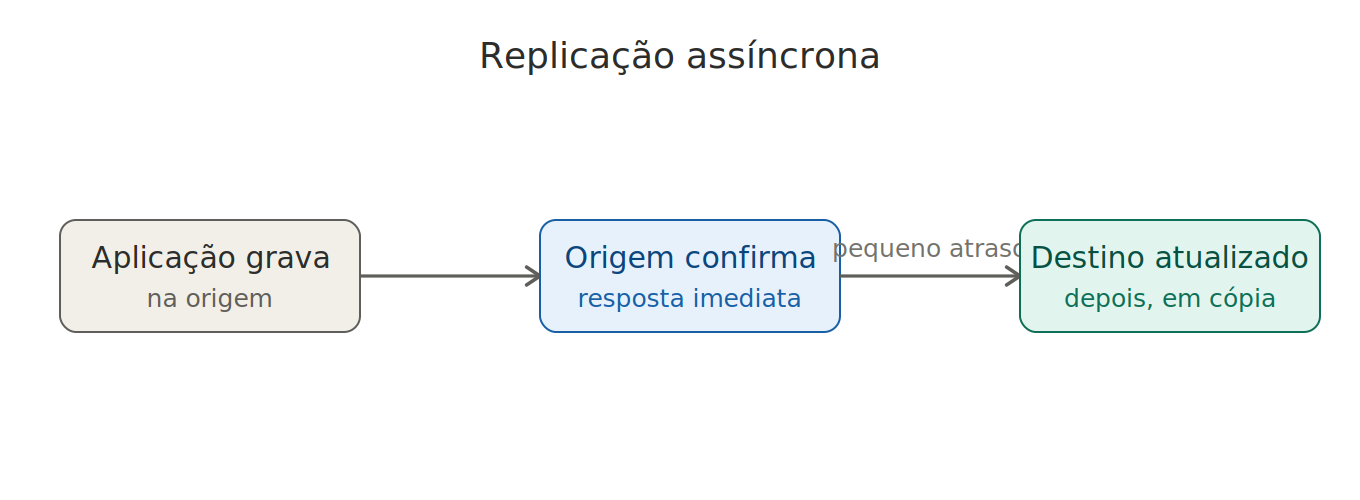
Replicação assíncrona
As informações são gravadas primeiro no ambiente principal e, após um pequeno intervalo, copiadas para os destinos. Esse leve atraso torna o processo mais flexível, econômico e ideal para cobrir longas distâncias geográficas ou operar em cenários com largura de banda limitada.
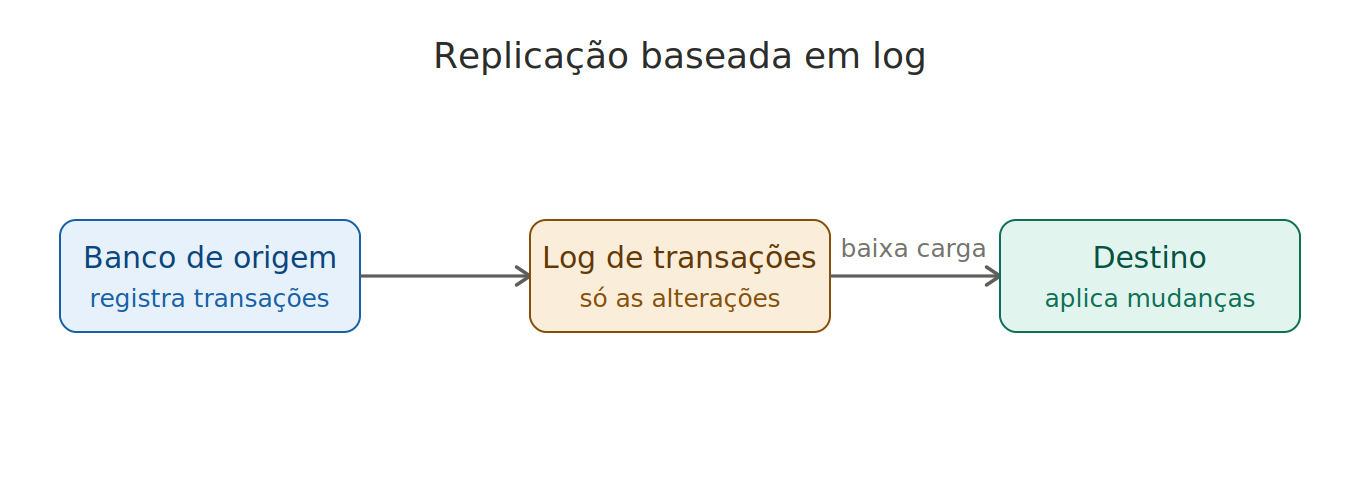
Replicação baseada em log
O sistema monitora diretamente o registro de transações (log) do banco de dados de origem e replica apenas essas operações no destino. Por transmitir estritamente as alterações realizadas, é um modelo leve que gera pouquíssima sobrecarga na rede.
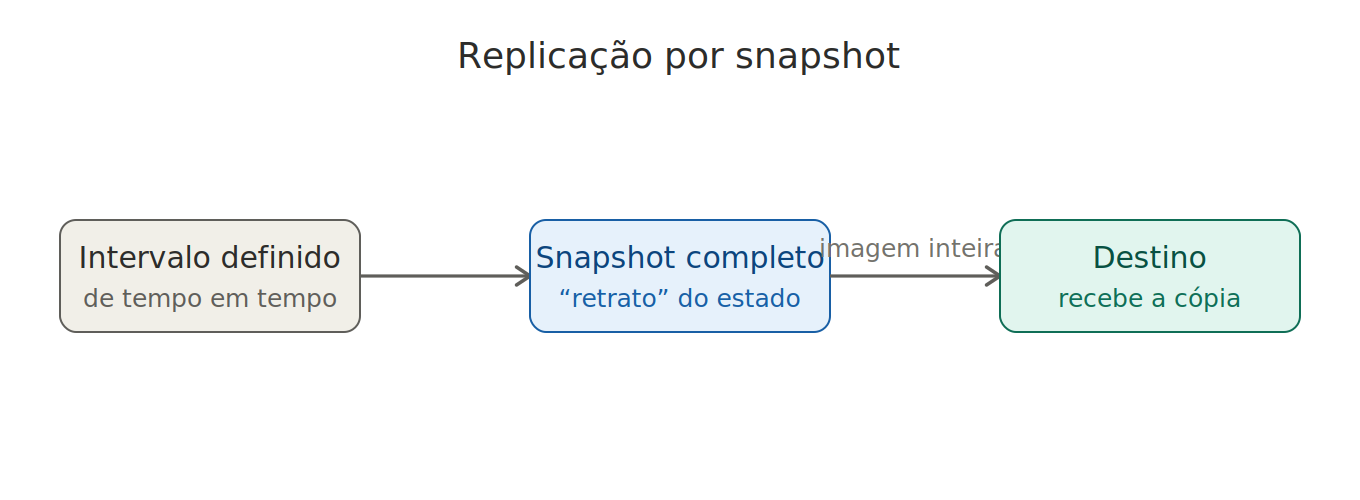
Replicação por snapshot
Em vez de copiar os dados transação por transação, o sistema tira um “retrato” completo do estado do ambiente em intervalos de tempo definidos e envia essa imagem ao destino. É uma escolha possível para sistemas que toleram alguma defasagem e buscam reduzir custos com infraestrutura contínua.
Como escolher o modelo de replicação para seu negócio?
Para escolher o modelo de replicação de dados ideal para o seu negócio, você deve avaliar o impacto que a indisponibilidade de sistemas e a perda de informações trariam para a operação. A decisão técnica deve ser nas metas de RPO (Ponto de Recuperação Objetivo) e RTO (Tempo de Recuperação Objetivo) da sua empresa, equilibrando o nível de proteção necessário com o orçamento disponível.
Analise os seguintes cenários para definir a melhor estratégia:
- Para RPO zero ou próximo de zero: se a sua operação lida com dados críticos e regulamentados (como transações financeiras ou prontuários médicos) e não pode perder nenhum dado, a replicação síncrona é indispensável, pois garante consistência imediata entre os ambientes;
- Para RPO de alguns minutos ou horas: se uma pequena margem de defasagem é aceitável e não compromete a continuidade do negócio, a replicação assíncrona ou por snapshot atende perfeitamente. Essas opções oferecem excelente custo-benefício e menor exigência de largura de banda;
- Abordagem híbrida em cenários mais complexos: hoje, as arquiteturas de TI raramente dependem de uma única resposta. O mercado frequentemente combina diferentes modelos, aplicando a replicação síncrona para os bancos de dados críticos e a assíncrona para sistemas de suporte ou relatórios menos sensíveis.
Além do fator tempo, considere também a distância geográfica entre o datacenter de origem e o de destino (grandes distâncias pedem replicação assíncrona para evitar latência) e o custo de infraestrutura, garantindo que a tecnologia escolhida seja sustentável para a empresa no longo prazo.
Quais as vantagens da replicação de dados?
Adotar uma estratégia de replicação de dados protege a operação contra prejuízos financeiros e operacionais. Para quem decide o futuro do negócio, essa tecnologia entrega quatro vantagens competitivas fundamentais:
- Garantia de Alta Disponibilidade (Business Continuity): se o sistema principal falhar, a réplica assume a operação imediatamente. Assim é possível eliminar o tempo de inatividade (downtime), garantindo que clientes e colaboradores continuem operando sem interrupções e evitando perdas de faturamento;
- Mitigação de riscos: manter os dados sincronizados em múltiplos locais protege o patrimônio de informação da empresa contra falhas de hardware, ataques cibernéticos ou desastres físicos, garantindo a segurança do histórico do negócio;
- Otimização do desempenho: ao distribuir réplicas dos dados, os usuários e sistemas (como ferramentas de BI e relatórios) podem acessar o servidor mais próximo ou menos sobrecarregado, reduzindo a latência da rede e eliminando os gargalos de performance no sistema de produção principal;
- Fundação para o Disaster Recovery (Recuperação de Desastres): a replicação é o motor que viabiliza um plano de Disaster Recovery eficiente. Ela garante que, no caso de um incidente grave, a empresa consiga realizar o failover (virada de chave para o ambiente secundário) com o menor impacto possível para o mercado.
Replicação de dados com a UDS
Desenhar uma estratégia de replicação de dados eficaz exige conhecimento profundo em arquitetura de infraestrutura, dimensionamento correto de custos e blindagem de segurança. Na UDS, nós transformamos essa complexidade técnica em estabilidade e previsibilidade para o seu negócio.
Com mais de uma década de experiência em projetos de alta complexidade e missão crítica, nossa atuação cobre todo o ciclo de vida da sua estratégia de dados:
- Mapeamento e consultoria: analisamos a arquitetura atual da sua empresa para identificar gargalos e mapear quais sistemas exigem replicação síncrona ou assíncrona, garantindo que você não gaste mais do que o necessário;
- Soluções Sob Medida: criamos topologias de replicação dimensionadas pela criticidade real de cada operação, equilibrando custos de banda e infraestrutura com o nível máximo de proteção de dados;
- Implementação e testes de failover: configuramos os ambientes de destino e validamos a virada de chave em cenários simulados para que os seus planos de continuidade e Disaster Recovery realmente funcionem antes que você precise deles;
- Governança e sustentação contínua: monitoramos o tráfego e a sincronia dos ambientes para evitar o corrompimento de dados e assegurar conformidade operacional em tempo integral.
Garantir que a sua empresa continue faturando e operando, mesmo diante de falhas críticas, é um investimento estratégico e não negociável. Se a sua operação precisa mitigar riscos e assegurar a continuidade do negócio, conte com a nossa expertise para desenhar ou revisar a sua estrutura.





