Downtime é o período em que um sistema, equipamento ou processo permanece indisponível, incapaz de cumprir sua função. Seja um servidor que sai do ar ou uma máquina parada na linha de produção, esse intervalo de inatividade faz com que a operação pare, e cada minuto costuma ser sinal de prejuízo financeiro, perda de produtividade e possíveis desgaste com clientes.
Para quem lidera tecnologia ou operações, entender as práticas para reduzir o downtime passa pelo entendimento de como medi-lo e, crucialmente, como identificar o que o causa. Um sistema considerado “estável” pode esconder horas de indisponibilidade ao longo do ano que só aparecem quando se passa a medir.
Neste guia, você vai entender o que é downtime em TI e na produção, o que pode causá-lo (inclusive na AWS), como ele é mensurado e quais passos seguir para reduzi-lo. Acompanhe:
O que é downtime?
De forma simples, como adiantamos, downtime (ou tempo de inatividade) é o período em que um sistema, máquina, processo ou operação inteira fica interrompida e indisponível. É o momento em que a produtividade para, seja por uma falha inesperada ou por uma pausa programada. Por isso, inclusive, o oposto do downtime é o uptime, que representa o tempo de funcionamento normal e ativo de uma operação.
Na prática, esse estado de inatividade pode estar presente em diferentes níveis e ativos de uma organização:
- Infraestrutura digital: como servidores de hospedagem caídos, instabilidades em bancos de dados e ferramentas de comunicação interna;
- Dispositivos físicos de trabalho;
- No caso de indústrias, em maquinários e linhas de produção paradas.
Em suma, onde quer que um recurso essencial para a operação deixe de funcionar, o downtime estará acontecendo ali:
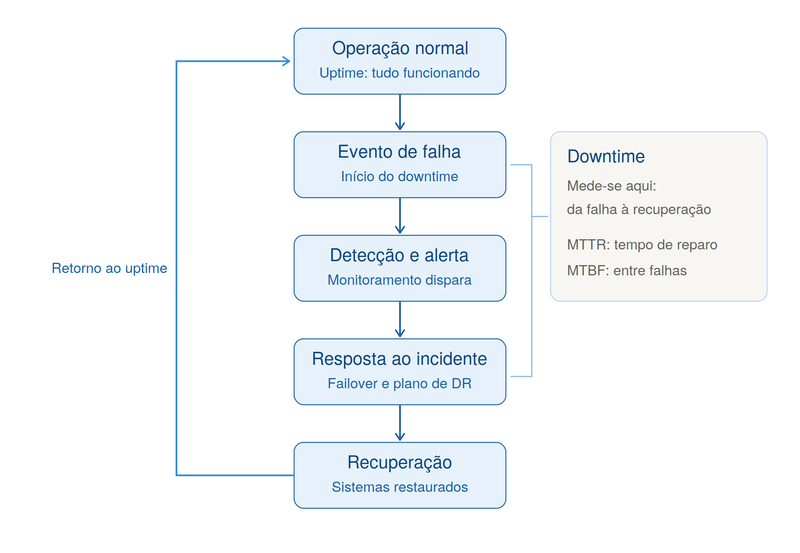
O que é downtime em TI?
Depois de entender o conceito geral, fica mais fácil de compreender que o downtime em TI é o tempo durante o qual um sistema, aplicação, servidor ou serviço fica indisponível para uso. Pode ser uma queda total — o site fora do ar — ou uma degradação que impede os usuários de concluir o que precisam, como um sistema lento demais para ser usável.
Nesse cenário, o downtime costuma ser dividido em duas categorias, e separá-las é essencial para medir bem:
- Downtime planejado: paradas programadas para manutenção, atualização ou deploy, normalmente feitas em janelas de baixo uso;
- Downtime não planejado: quedas inesperadas por falha de hardware, erro de software, ataque cibernético ou problema de infraestrutura. Este é o tipo que mais gera prejuízo, justamente por ser imprevisível.
O impacto do downtime em TI pode significar transações perdidas, contratos com SLA descumpridos e abalo na confiança do cliente. Por isso, reduzir o downtime se conecta diretamente a estratégias de continuidade, como o Disaster Recovery, que define como restaurar a operação quando a falha acontece.
O que é downtime na produção?
Na indústria, downtime é o período em que uma máquina, linha ou planta deixa de produzir. É o estado de inatividade em que um equipamento, sistema ou processo permanece impossibilitado de cumprir sua função operacional pretendida. Aqui também vale considerarmos a distinção entre paradas planejadas (manutenção preventiva, troca de ferramental, setup) e não planejadas (quebras, falhas de insumo, ajustes emergenciais).
O downtime industrial é um dos principais indicadores de eficiência: ele alimenta métricas como o OEE (Overall Equipment Effectiveness) e revela custos ocultos com manutenção emergencial e ociosidade. Quanto mais cedo uma parada não planejada é prevista e evitada, menor o impacto sobre a produtividade e o custo da operação.
Como mensurar o downtime?
Para transformar o tempo de inatividade em uma métrica que se alinhe à tomada de decisão, você deve ir além do simples rastreio de horas paradas: é importante correlacionar a estabilidade técnica ao impacto financeiro e ao cumprimento de SLAs.
Veja um plano de ação para mensurar o downtime com precisão técnica:
1. Estabeleça o cálculo da Disponibilidade Real (Availability)
Monitore a saúde do seu ecossistema digital calculando a porcentagem de tempo em que os sistemas permaneceram operacionais em relação ao período planejado. Para fazer isso, utilize a fórmula:
- Disponibilidade (%) = (Tempo Ativo Real / Tempo Total Planejado) x 100
Se a sua plataforma deveria operar por 100 horas em uma semana, por exemplo, mas sofreu uma queda não planejada de 5 horas, sua disponibilidade foi de 95%. Utilize essa métrica para avaliar o custo de oportunidade e a perda de receita por minuto de ociosidade.
2. Defina a sua meta com base na “Regra dos Noves”
A alta disponibilidade em TI é medida pela quantidade de “noves” após a vírgula. Cada fração representa um salto tecnológico na arquitetura de infraestrutura (como redundância e multi-cloud) e um custo de investimento diferente.
Alinhe a tolerância do seu modelo de negócios a esses parâmetros:
- 99,9% de disponibilidade (Três Noves): permite até 8,7 horas de downtime por ano. É o padrão aceitável para aplicações internas ou sistemas cujo impacto de uma parada curta não seja catastrófico.
- 99,99% de disponibilidade (Quatro Noves): Tolera apenas cerca de 52 minutos de indisponibilidade anual. Essencial para plataformas core, e-commerces de alto volume e operações críticas.
Avalie o equilíbrio financeiro: cada “nove” adicionado exige um investimento crescente em infraestrutura. Então, descubra onde está o ponto de equilíbrio entre o custo de manter o sistema resiliente e o prejuízo da queda.
3. Monitore os indicadores de resiliência (MTBF e MTTR)
Para gerenciar crises de engenharia de forma preditiva, implemente e acompanhe dois indicadores fundamentais:
- Aumente o MTBF (Mean Time Between Failures): calcule o tempo médio entre as falhas dividindo o tempo total de operação pelo número de incidentes. O seu objetivo estratégico aqui é aumentar esse intervalo, o que prova a estabilidade do código e da infraestrutura;
- Reduza o MTTR (Mean Time to Repair): calcule o tempo médio de reparo dividindo o tempo total de indisponibilidade pelo número de intervenções. Reduza esse indicador aplicando automação de monitoramento, alertas em tempo real e playbooks de Disaster Recovery. Quanto menor o MTTR, mais rápida é a resposta do seu time técnico para reestabelecer o negócio.
Quer garantir alta disponibilidade, segurança e zero prejuízo com sistemas fora do ar? Fale com os especialistas da UDS e desenhe uma arquitetura de software robusta e escalável pensada para o seu negócio.
Como reduzir o downtime?
Reduzir o downtime depende de antecipar falhas, construir redundância e ter um plano de resposta testado. Os passos abaixo valem tanto para ambientes de TI quanto, com adaptações, para operações industriais:
1. Monitore e meça continuamente
Não dá para reduzir o que não se mede. O primeiro passo é instrumentar a operação com monitoramento em tempo real, registrando cada parada (planejada ou não) para criar uma linha de base e identificar padrões.
Comece configurando alertas automáticos para os indicadores que sinalizam problema antes da queda total:

- Disponibilidade (uptime): o percentual de tempo no ar, comparado à meta de SLA definida;
- Tempo de resposta e latência: degradações costumam anteceder quedas, funcionando como alerta precoce;
- Taxa de erros: picos de erros (como respostas HTTP 5xx em TI) indicam falha em curso;
- Uso de recursos: CPU, memória, disco e rede próximos do limite antecipam a saturação.
Com esses dados registrados ao longo do tempo, você passa a enxergar tendências (por exemplo, que determinada falha sempre ocorre em horário de pico) e a agir sobre a causa, e não apenas sobre o sintoma.
2. Construa redundância
Em seguida, elimine pontos únicos de falha. Seja ao distribuir a operação entre múltiplas zonas e regiões, com réplicas prontas para assumir, ou ao manter peças e ativos críticos de reserva, o nível de redundância deve ser proporcional à criticidade de cada sistema. Uma forma de calibrar isso:
| Criticidade do sistema | Estratégia de redundância | Exemplo |
| Crítica (não pode parar) | Réplicas ativas em múltiplas regiões, com failover automático | Sistema de pagamentos, ERP central |
| Média | Réplica pronta em outra zona, ativada sob demanda | Portais internos, aplicações de apoio |
| Baixa | Backup recuperável, sem ambiente em espera | Relatórios, ambientes de teste |
A regra geral é simples: identifique cada componente do qual a operação depende inteiramente e garanta que exista um substituto pronto para assumir sem intervenção manual.
- Leia também: Como criamos a infraestrutura Cloud do melhor meio de pagamento do Brasil, usando uma abordagem DevSecOps
3. Adote manutenção preventiva e preditiva
Em vez de só reagir à quebra, antecipe-a através de ferramentas como a manutenção preventiva, que atua em intervalos programados, e a preditiva, que usa dados e monitoramento para agir antes da falha prevista, reduzindo as paradas não planejadas, que são as mais caras.
A diferença entre as três abordagens de manutenção define o quanto de downtime não planejado você consegue evitar:
- Corretiva: atua depois que a falha já ocorreu. É a mais cara, porque a parada é inevitável e imprevisível;
- Preventiva: atua em intervalos fixos (por tempo de uso ou calendário), trocando ou revisando antes do desgaste esperado;
- Preditiva: monitora o estado real do ativo ou sistema e só intervém quando os dados indicam que a falha se aproxima, evitando tanto a quebra quanto a troca desnecessária.
O caminho ideal é migrar progressivamente do corretivo para o preditivo nos ativos e sistemas mais críticos, concentrando esforço onde uma parada custa mais.
4. Tenha um plano de recuperação testado
Documente como a operação será restaurada, com responsáveis e sequência de ações definidos, e teste esse plano com regularidade. Afinal, um plano que nunca foi exercitado costuma revelar falhas justamente durante o incidente real.
Um plano de recuperação eficaz precisa responder, por escrito e com antecedência, a quatro perguntas:
- Quem faz o quê? os papéis e responsabilidades de cada pessoa durante o incidente;
- Em que ordem? a sequência de prioridade de recuperação dos sistemas, do mais crítico ao menos;
- Em quanto tempo? as metas de RTO (tempo máximo até restaurar) e RPO (volume máximo de dados que se pode perder);
- Como validamos? a rotina de simulações periódicas que comprova que o plano funciona.
Leia também: Cloud resilience: como garantir continuidade de negócios e segurança de dados
5. Automatize a resposta a incidentes
Quanto menos a recuperação depender de ação manual sob pressão, mais rápida e confiável ela será. Por isso, failovers automáticos, alertas e rotinas de autocorreção encurtam o tempo entre a falha e a retomada.
A automação atua em três frentes que, juntas, reduzem drasticamente o tempo de resposta:
- Detecção: alertas disparados automaticamente no primeiro sinal de anomalia, sem depender de alguém perceber o problema;
- Recuperação: failover e rotinas de autocorreção que redirecionam a operação para um ambiente saudável sem intervenção humana;
- Escalonamento: acionamento automático da pessoa certa quando a automação não resolve sozinha, evitando que o incidente fique sem dono.
O objetivo não é eliminar o time da equação, mas reservar a ação humana para as decisões que realmente exigem julgamento, deixando o que é repetitivo e urgente a cargo da automação.
Como reduzir o downtime na planta industrial?
Na planta industrial, os mesmos princípios se aplicam com foco nos ativos físicos: priorize a manutenção preditiva sobre os equipamentos críticos, mantenha um inventário de peças de reposição, padronize procedimentos de setup para reduzir paradas planejadas e use indicadores como OEE e MTTR para direcionar onde investir.
A digitalização do chão de fábrica com sensores e sistemas que monitoram os equipamentos em tempo real é o que permite migrar de uma postura reativa para uma preditiva.
O que pode causar downtime na AWS?
Mesmo provedores de nuvem robustos como a AWS estão sujeitos a downtime, e entender as causas ajuda a desenhar arquiteturas mais resilientes. As mais comuns são:
- Falhas de configuração e automação: erros em sistemas internos que se propagam rapidamente;
- Problemas de DNS: quando o serviço que “traduz” endereços falha, as aplicações simplesmente não encontram os recursos de que dependem;
- Concentração em uma única região: depender de uma só região (especialmente a us-east-1, a maior e padrão da AWS) amplia o raio de impacto de qualquer incidente;
- Efeito cascata entre serviços: quando um serviço-base falha, outros que dependem dele caem em sequência.
O exemplo mais marcante recente que ilustra bem issoé que, em 19 e 20 de outubro de 2025, a região us-east-1 da AWS sofreu uma grande interrupção: o que começou como uma falha de DNS no DynamoDB se desdobrou em uma interrupção do EC2 que se estendeu por mais doze horas até o serviço normalizar. O incidente começou como uma falha de DNS afetando os endpoints do DynamoDB, mas rapidamente se propagou pelo ecossistema de serviços da AWS, atingindo plataformas globais como Fortnite, Roblox, Snapchat e Coinbase.
A lição que fica, então, é que a resiliência vem de arquitetar a operação para que, quando ocorra, o impacto seja contido.
- Sabia que a UDS é reconhecida como Parceira Nível Advanced AWS? Clique e saiba como podemos te ajudar!
Reduza o downtime com a UDS
Para maior resiliência contra o downtime, é essencial contar com maturidade em engenharia de software, conformidade rigorosa e arquiteturas de nuvem sob medida. Para marcas com ecossistemas robustos e tolerância zero a falhas, a estabilidade dos sistemas está diretamente ligada à proteção da receita e da reputação. É com esse mesmo rigor executivo que a UDS desenha estratégias de mitigação de riscos:
- Redundância dimensional: arquiteturas planejadas com base na criticidade real e no impacto financeiro de cada fluxo da operação;
- Monitoramento preditivo: mitigação proativa de incidentes através de visibilidade total da infraestrutura, agindo antes que o usuário seja afetado;
- Continuidade de negócios: engenharia focada em baixos índices de MTTR através de playbooks de Disaster Recovery testados sob estresse.
Sua operação não pode parar. Fale com um especialista da UDS e blinde a arquitetura dos seus sistemas contra o downtime.




