A explosão das arquiteturas serverless está redefinindo as regras do jogo no desenvolvimento e na gestão de aplicações. Mais do que um avanço, esse tipo de arquitetura desafia estratégias de monitoramento e observabilidade afinal, manter a estabilidade de soluções exige um olhar atento e meticuloso sobre os indicadores vitais de suas aplicações serveless. E entender o que está lento, quebrado ou que precisa de atenção é importante para manter a disponibilidade.
Neste artigo, vamos explorar as métricas obrigatórias do CloudWatch para Lambda, SNS e SQS, que vão manter suas aplicações serverless a todo vapor e tirar o máximo potencial delas.
Monitoramento: o check-up básico
O serviço de monitoramento serverless oferece a capacidade de acompanhar, analisar e aperfeiçoar suas aplicações. Adaptado ao design específico da arquitetura orientada por eventos (EDA), esse tipo de monitoramento é tailor-made para o contexto serverless. Ele emprega métricas precisas para sinalizar às equipes eventuais problemas, o que garante uma operação fluida e eficiente.
Imagine o monitoramento da sua aplicação serverless como um check-up regular com seu médico. Essa é a sua linha de defesa inicial, que assegura que os batimentos cardíacos de sua infraestrutura, desde a execução básica até a operação de módulos de software específicos, estejam funcionando sem problemas.
Em um ambiente serverless, onde você delega a gestão da infraestrutura à AWS, o monitoramento torna-se crucial para identificar e remediar rapidamente qualquer disfunção operacional.
A importância da observabilidade
Embora frequentemente usados como sinônimos, observabilidade e monitoramento não são conceitos idênticos. Monitoramento refere-se à coleta de métricas e logs predefinidos, fornecendo uma visão superficial da saúde do sistema. Por outro lado, a observabilidade permite uma introspecção profunda, o que capacita as equipes a entender e diagnosticar estados desconhecidos do sistema, indo além das métricas predefinidas para explorar o desconhecido.
Dessa forma, se o monitoramento é o check-up, a observabilidade é seu teste de condicionamento físico, e assegura não só que cada parte está funcionando como deveria, mas que estão trabalhando juntas de forma eficiente para cumprir tarefas.
Ferramentas como o AWS CloudWatch são essenciais, pois oferecem insights detalhados sobre cada aspecto de sua aplicação, e permitem uma compreensão profunda do “porquê” por trás do comportamento dos sistemas.
Aqui está uma aplicação serverless típica que processa eventos que disparam outros serviços da AWS:

Tratado como uma operação atômica, é importante rastrear o que está acontecendo entre os serviços e identificar quaisquer problemas e por que eles ocorrem. As cinco coisas que você vai querer ficar de olho são:
- Limites de Concorrência: monitora quantas instâncias executam ao mesmo tempo para evitar ultrapassar limites estabelecidos;
- Erros: observa falhas na execução das funções para correção rápida e manutenção da saúde da aplicação;
- Falhas na DLQ (Dead Letter Queue): identifica mensagens que não foram processadas, sinalizando problemas que necessitam correção;
- Falhas na entrega de destino: verifica problemas ao enviar dados a outros serviços, indicando falhas de conectividade ou configuração;
- Idade das mensagens em stream: mede o tempo de espera das mensagens para processamento, ajudando a evitar atrasos.
Navegando pelos desafios de performance e erros em aplicações serverless com AWS
As aplicações serverless, especialmente aquelas construídas sobre o AWS Lambda, oferecem uma elasticidade e escalabilidade significativas, o que permite que empresas se adaptem rapidamente a variações de demanda sem o ônus de um planejamento de capacidade prévio.
No entanto, gerenciar e otimizar o desempenho dessas aplicações requer um olhar atento a certos indicadores-chave e a implementação de alertas estratégicos. Vamos explorar como você pode utilizar as métricas e alertas para manter suas aplicações serverless rodando de forma suave e eficiente.
Alertas para picos de desempenho com AWS Lambda
AWS Lambda é uma ferramenta formidável que se ajusta automaticamente a picos de demanda, mas é vital compreender a frequência e o volume dessas invocações. Com limites padrão de 1000 invocações simultâneas por região, um olhar cuidadoso para a métrica de execuções simultâneas torna-se indispensável.

→ Um exemplo da medição com as métricas de execuções simultâneas:
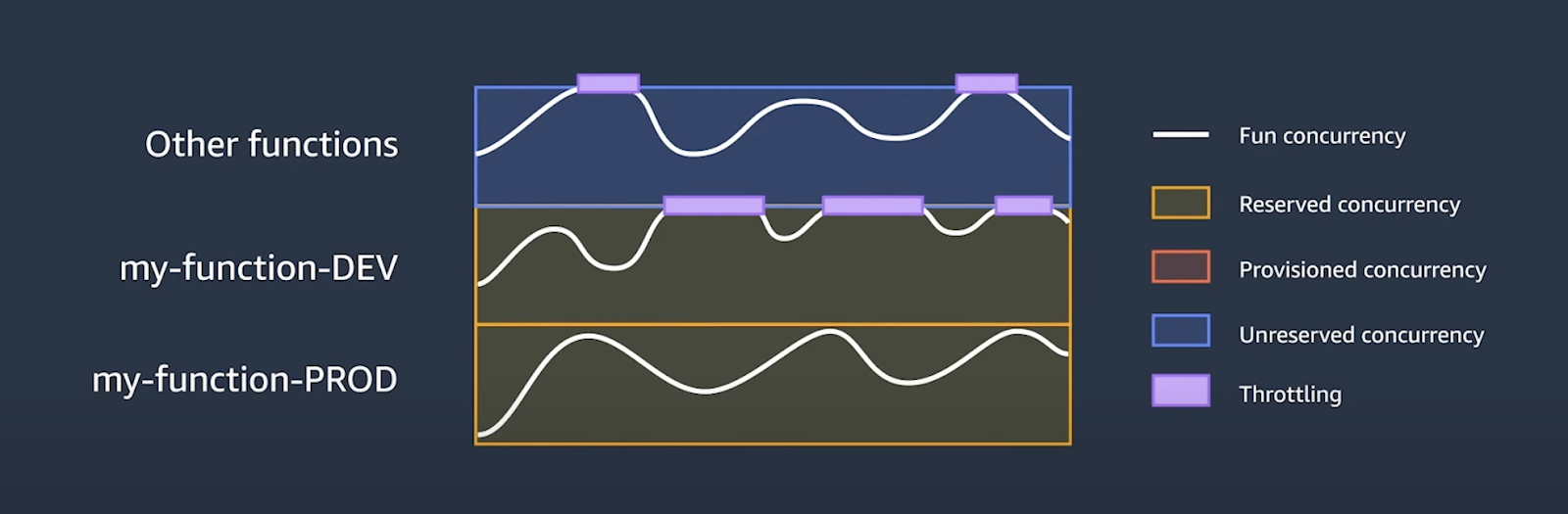
Pense nisso como a unidade de escala. Configurar um alerta em torno de 80% é uma boa maneira de ver quando e com que frequência você está se aproximando do máximo. Dependendo das necessidades de tempo de resposta da sua aplicação, você pode considerar a métrica de limites de rejeição se não estiver usando limites de concorrência reservados.

O desafio dos falsos positivos
É preciso cautela ao configurar esses alertas, já que eles também podem levar a falsos positivos. Ajustar seus alertas para refletir as necessidades reais de tempo de resposta da sua aplicação e as peculiaridades do seu ambiente operacional pode ajudar a mitigar esse risco.
Alertas e cálculo de taxas de erro com AWS CloudWatch
Em seguida, vamos dar uma olhada nos alertas de erro. Se suas funções Lambda estiverem gerando muitos erros, isso pode causar uma degradação real na experiência do usuário e deixá-lo bastante irritado também. Compreender a taxa na qual esses erros estão ocorrendo é realmente importante.
É aqui que entra a matemática que o CloudWatch usa para calcular as taxas de erro. A sacada é ajustar o limiar de alerta para o seu Acordo de Nível de Serviço. Por exemplo, se o seu SLA estipula que 99% das funções devem ter sucesso, então defina o alerta de taxa de erro para 1%. Vários serviços da AWS, como SNS e S3, processam seus eventos de forma assíncrona.
Vale lembrar ainda que o Lambda coloca os eventos em uma fila de mensagens mortas (Dead Letter Queue), e um processo separado realmente os lê antes de enviá-los para sua função. Ele tenta executá-lo três vezes com esperas de um minuto nas duas primeiras tentativas, depois três na terceira tentativa, antes de retornar um erro. As funções podem ter erros de permissão, recursos mal configurados ou atingir limites de tamanho.
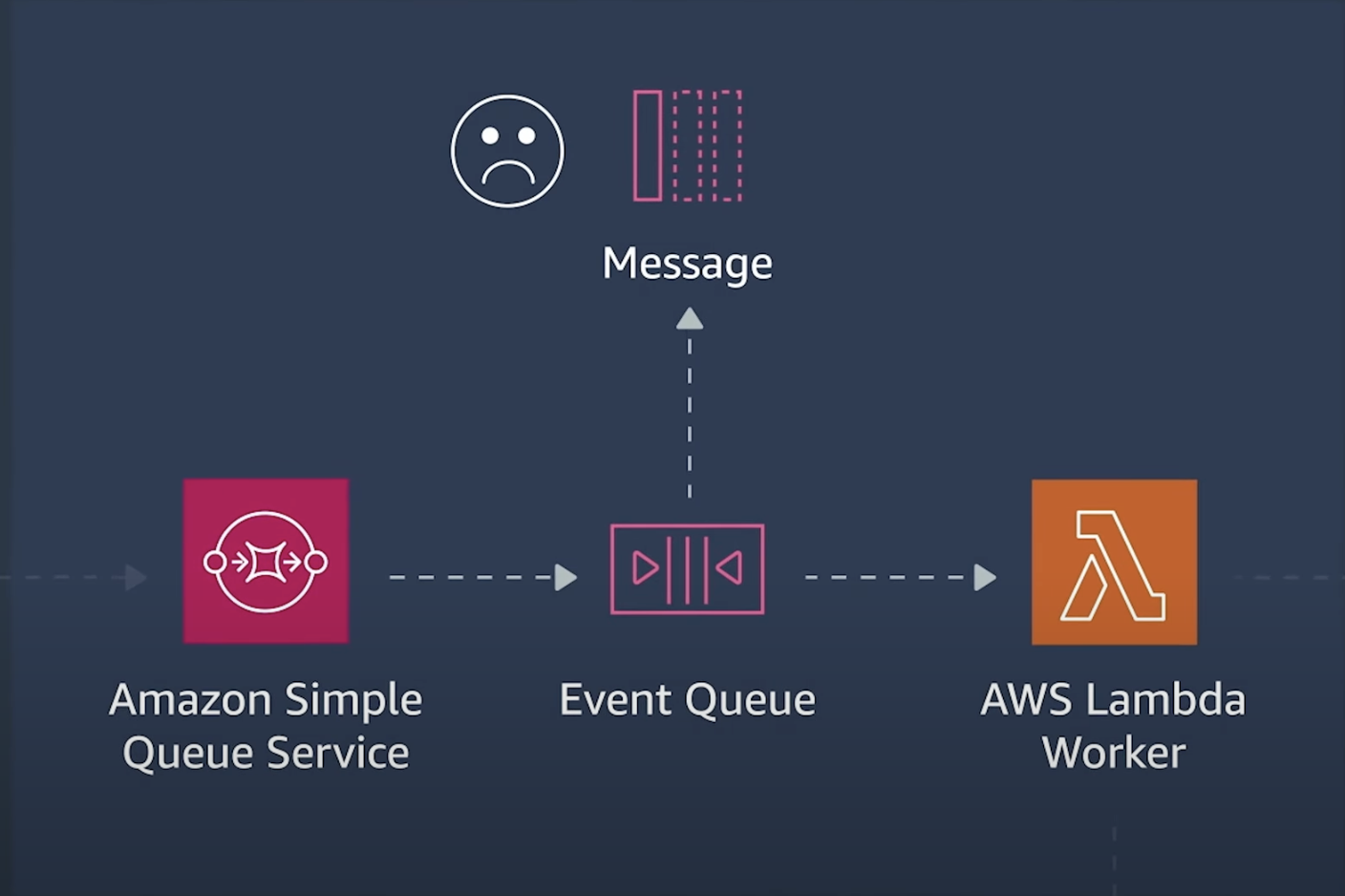
Portanto, configurar uma métrica de erro de Dead Letter Queue permite que você acompanhe quantas vezes isso acontece. Semelhante às filas de mensagens mortas (DLQ), as funções podem enviar um evento para um destino. Estes podem ser uma SQSQ, um tópico SNS, uma função Lambda ou um barramento de eventos. Todos podem falhar, então configurar um alerta contra uma métrica de falha na entrega do destino é uma boa ideia.
Analisando o desempenho e a eficiência das funções
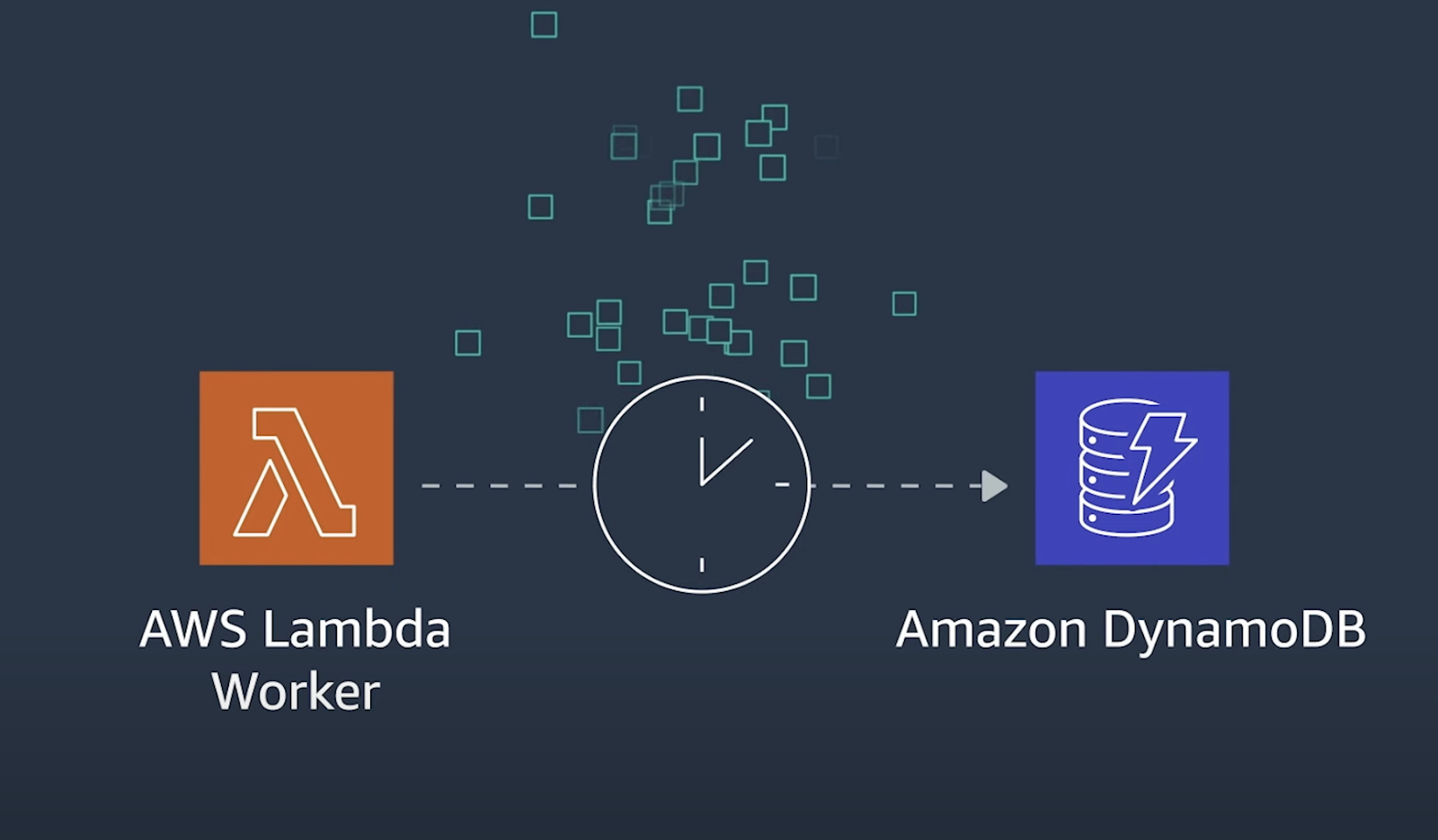
Outro aspecto crucial é monitorar a “idade do iterador” em serviços de streaming como Kinesis ou Kafka. Essa métrica indica o tempo de processamento das mensagens, servindo como um indicador de desempenho. Um aumento nessa métrica sugere que a aplicação está atrasada na leitura de novas mensagens, potencialmente levando a perda de dados.
No pior dos casos, você pode experimentar perda de dados, já que os dados nos fluxos são mantidos apenas por 24 horas por padrão.
Proatividade como chave para o sucesso
Em conclusão, o monitoramento e a observabilidade não são apenas ferramentas reativas; elas são a espinha dorsal de uma estratégia proativa para manter suas aplicações serverless com bom desempenho. Implementando os alertas sugeridos e mantendo-se vigilante às métricas, você garante não apenas a saúde operacional da sua aplicação, mas também oferece uma experiência de usuário impecável.
Lembrando sempre que, em um ambiente serverless, onde muitos aspectos da infraestrutura não são gerenciados para você, a atenção aos detalhes no monitoramento e na observabilidade permite que você mantenha certo nível de controle, otimize recursos e, o mais importante, antecipe-se aos problemas antes que eles impactem seus usuários.
Desfrute dos benefícios da nuvem com confiança e segurança.
Descubra mais nos conteúdos a seguir:
Gostou desse conteúdo e quer saber mais sobre como a Consultoria Cloud da UDS pode te ajudar a ter ainda mais performance? Preencha o formulário para saber mais:




